Kafka简单总结
Kafka整体架构
一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Topic & Partition & consumer group
Topic在逻辑上可认为是一个队列,每条消息都必须制定它的Topic,也就是指明放在哪个队列上。为了提高Kafka的吞吐率,物理上把Topic分成一个或多个partition,每个Partition在物理上是一个文件夹,包含这个partition的所有消息,以及消息的索引, 消息存储在日志文件中,消息格式如下:
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
这个log entry并非由一个文件构成,而是分成多个segment,每个segment以该segment第一条消息的offset命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。
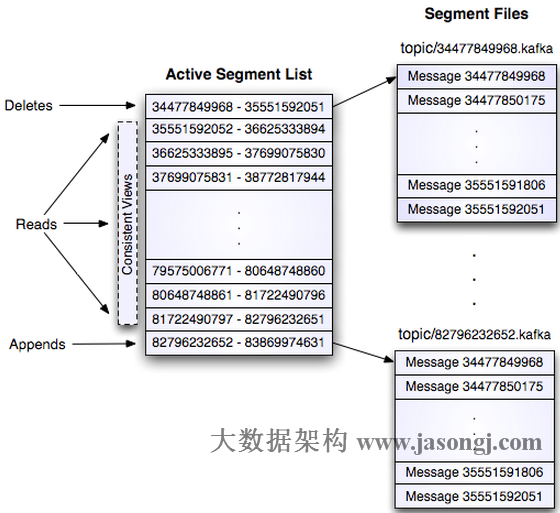
每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高.
每个partition的消息能够保序, 消息全局不保序。
同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
kafka的消费者消费消息是采用pull模式。
Kafka会为每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。
Kafka HA
- kafka 为了避免broker宕机引起的不可用问题,引入Replication来保证高可用。
- 为了解决引入replica所带来的消息复制效率问题,引入leader来解决这个问题,保证leader写成功,并且确保isr都写入成功。
- leader选主通过类似PacificA算法。
注:后续需要详细研究一下。